Related link: Cube Load
For huge data models, it may not be convenient to load the data at the most detailed level to an OLAP cube. However, access to this detailed data is required for the analysis. This is the scenario for drillthrough: the data are stored at an aggregated level in a cube. With a drillthrough request on a cube cell from the front end, the detailed data, including additional fields (e.g. Order Number, Line Item ID), can be displayed.
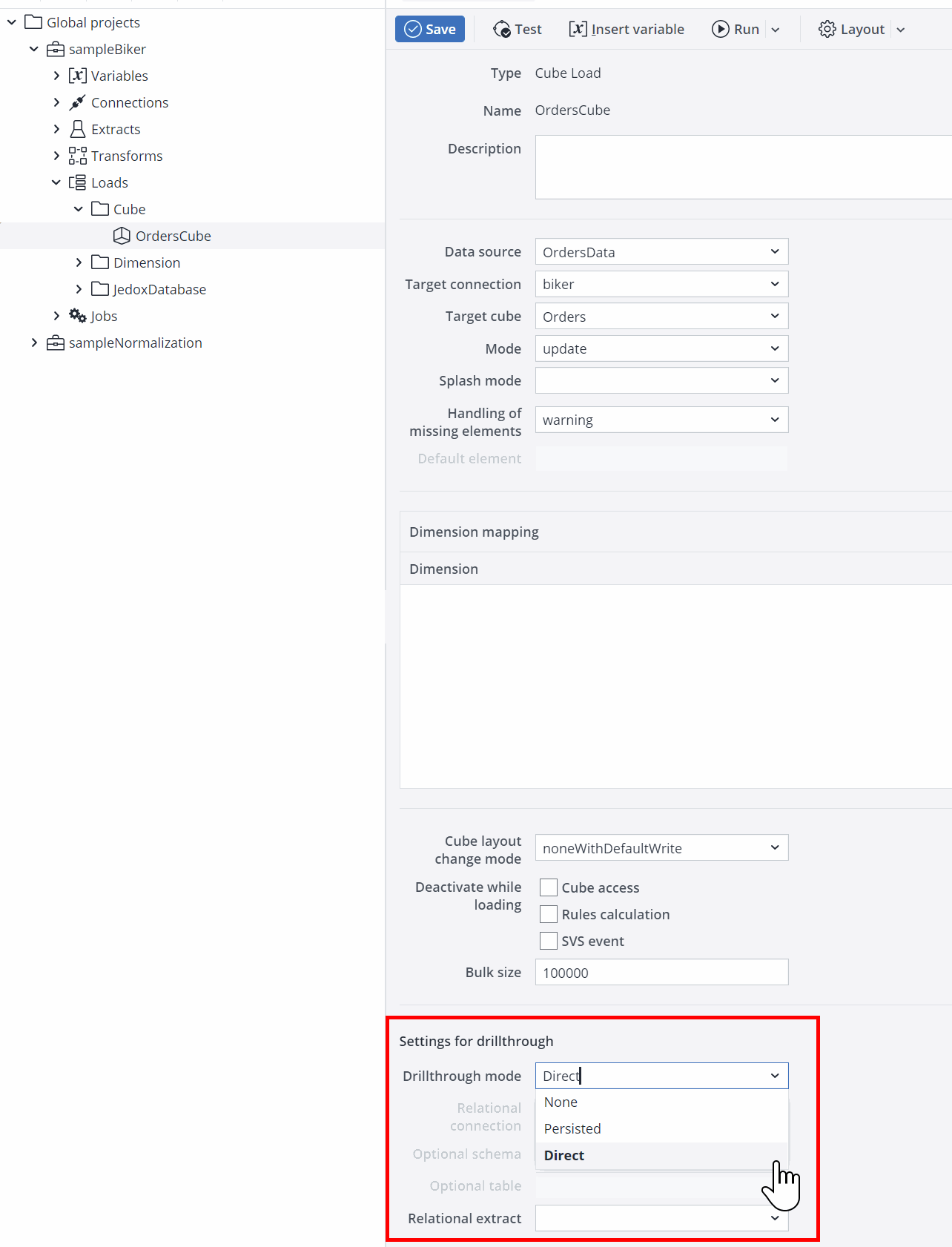
Drillthrough can be enabled in the settings area of a cube load. Select the desired drillthrough mode from the dropdown list, as shown below.
Drillthrough requests are possible with Jedox Excel Add-in and Jedox Web. For the configuration of the drillthrough, you need to install and configure Jedox Supervision Server.
To retrieve the drillthrough data via Integrator, use the cube extract with advanced option "Retrieve drillthrough data". For an example, see the Jedox sample Integrator project sampleDrillthrough.
Definition of annex fields
The columns of the source that should be part of the detailed drillthrough data request (but not part of the cube) have to be defined. This can be done in the Dimension Mapping table by assigning the entry "" instead of a dimension name to the particular column. It is not necessary for these additional fields to be at the end of the source. The order of the columns in the source defines the display order.
Drillthrough modes
| None | The default setting for cube load is None, which means drillthrough is disabled. To enable drillthrough, select one of the drillthrough modes described below. | |||||||||
| Direct | No additional persistence of the detailed drillthrough data is done during the cube load. The requirement for this is that all detailed data can be retrieved via one relational extract without any further transforms. Only the link from the OLAP cube to this relational extract is stored in Jedox Integrator. Relational extract (for direct drillthrough only): all detailed data can be retrieved through a relational extract during a drillthrough request. It may contain an arbitrary SQL SELECT statement (using a stored SQL procedure is not supported). The relational extract may have a field structure with a column mapping, but it must not contain default values for the columns. Comments starting with /* are allowed, but not comments starting with -- (two hyphens). A field structure should be defined in the corresponding relational extract (button "Refresh" in table "Field structure"). The column "Field name" may be filled or not. This increases the performance of the drillthrough request, especially in the case of complex SQL statements, as it omits an initial SQL query to the database to determine the output columns of the relational extract. |
|||||||||
| Persisted | During the cube load, the detailed drillthrough data, including the additional fields, is additionally persisted to a relational database. The link from the OLAP cube to this relational table is stored in Jedox Integrator. Options for persisted drillthrough only:
Persisted drillthrough is not possible with "Cube layout change mode" set to "addDimensions", "updateDimensions", or "reorderDimensions". Adding or removing a column to a cube that is loaded with drillthrough has to be done manually in the Modeler and the relational database table with an external database tool. This is only possible when using an external connection for the drillthrough. To add a column for the drillthrough data only (data that is not a dimension of the cube) changing the database table manually is sufficient. Furthermore, additional columns to the relational table are only included with load mode "Create". With other load modes, they are ignored during the load and a warning is raised. As said above, these columns could be added manually to the relational table if an external relational database connection is used. |
|||||||||
Differences between persisted and direct drillthrough
| Persisted | Direct | |
| Data transformations | Allowed | Not allowed (only in SQL query) |
| Performance | Slightly higher query performance (if direct drillthrough with complex SQL query) | Higher loading performance, as no loading to relational persistence |
| Data accuracy | Consistent with cube data if the relevant cube slice is always loaded in a cube load with activated drillthrough (and the same connection, schema, and table). | Always up to date but potentially different from cube data. Consistency depends on the correct definition of the SQL query in the relational extract used for drillthrough. |
| Possible systems for source data | Any | One relational database system |
| Needed requirements | With external database: the Jedox Integrator project and the relational connection specified in the cube load must not be removed or renamed in order to find the correct data in a drillthrough request. With internal database: |
The Jedox Integrator project and the relational extract specified in cube load must not be removed or renamed in order to find the correct data in a drillthrough request. |
Notes:
-
If a dimension element is not found, by default, a warning is raised and the cube data will not be loaded, although the drillthrough data will be persisted. To avoid this, the option "Handling of missing elements" could be set to "createUnderDefault" or "createUnderDefaultParent".
-
The link of a cube to a drillthrough table can be displayed and removed in the Modeler.
-
The "splash" mode has to be set to "disabled" for all load modes, because no splashing can be done on the relational drillthrough data. This implies that only base elements can be handled in the source data.
-
It is not possible to run several cube loads with drillthrough for the same cube in parallel jobs.
-
Any manual changes to the cube slice relevant for drillthrough and to the cube layout will lead to inconsistencies in the drillthrough request. The same goes for manual changes to the relational table used in persisted drillthrough.
-
The cube load mode "insert" is not available in combination with drillthrough, as it might lead to inconsistencies between the cube and the detailed drillthrough data. Instead, the load mode "add" should be considered, possibly in combination with a preceding load mode "delete". For a cube load without drillthrough and a separate relational load for the drillthrough data (using relational load mode "insert" with "aggregation" option activated), it would be possible to achieve consistency but without linking the cube to the drillthrough table.
-
For a cell path for which no cell exists in the OLAP cube, no drillthrough values are displayed.
-
If rows with 0 or empty values are loaded in a Cube Load with persisted drillthrough and no cube cell is created in the cube, those rows won't be returned in a drillthrough request on this cube.
H2 connection (on-prem)
For on-prem customers and versions up to 21.4, the default connection for persisted drillthrough is an internal file-based H2 database, which is located in this directory: <install_path>\tomcat\webapps\etlserver\data\db\etl_drillthrough. It can be configured in file <install_path>\tomcat\webapps\etlserver\config\connections.xml
The H2 database should only be used for a small or medium-sized data volume (filesize 4GB maximum). For huge data, an external client-server-based database should be used, e.g. Postgres. With H2 as persistence, parallel drillthrough requests are handled sequentially. See also the H2 documentation.
The used storage of a drillthrough request can be seen from the logs in Integrator: a message starting with "Opening JDBC connection for URL: jdbc:h2:/" indicates the usage of H2 storage.
Updated July 3, 2025