To achieve maximum performance, Jedox In-Memory DB implements several engines for rule evaluation. When a database query is received, it is analyzed and checked against metadata (dimensions, cubes, elements, rules) and data (base cell values) that can influence the result. Based on the attributes of the metadata, Jedox generates a calculation plan and asks each engine if this plan can be executed on the given engine to provide the correct result.
Jedox In-Memory DB uses the following engines:
While the Structure-Driven Engine can evaluate every plan, it can be very slow in processing some queries. If multiple engines can process the plan, they provide an estimate for the maximum time they will spend processing the query. The engine with the shortest estimated time is then chosen and used for query processing.
Engine Configuration
There are some configuration parameters for the Jedox In-Memory Database Server that allow certain features of the calculation and rule engines to be turned on or off. The parameters are defined in the palo.ini configuration file by adding the entry engine-configuration followed by a list of desired features, as shown in the example below:
engine-configuration [engine_switch_code]*
# Example:
engine-configuration 1e
Multiple features can be defined by using the following flags:
| 1 | Disable multi-core calculation of rules |
| m | Force processing of markers, even for rules that the default engine would ignore |
| s | Disable the Dynamic-Marker-Driven Engine, and use the legacy Static-Marker-Driven Engine instead |
| e | Suppress rule-calculation errors |
| c | Automatically convert any GPU-enabled cubes to CPU storage when starting |
| g | Automatically convert any applicable cube to GPU storage on startup |
| r | It behaves like s and can be used instead of it, but it allows you to use the Static-Marker-Driven Engine without rebuilding the markers when the values are deleted and the rules are destroyed. It also generates the necessary markers when a child is added to a consolidated element, used as a source for marker rule. |
Structure-Driven Engine
The Structure-Driven Engine (SDE) is the oldest and most straightforward implementation. The target area of a rule is evaluated cell by cell in a virtual machine built into Jedox In-Memory DB. Single-cell calculation is quite fast, e.g. 10-100 µs (microseconds) per cell. However, it can be slow with the calculation of large areas. A rule-calculated area of 10.000.000.000 cells (10.000 x 1.000 x 100 x 10 elements) cells can take 10 days to be evaluated by the Structure-Driven Engine. The engine is, however, very flexible and supports 100% of rules functionality.
Static Marker-Driven Engine
The Static Marker-Driven Engine (SMDE; also called Marker-Driven Engine, or MDE) has been in existence almost as long as the Structure-Driven Engine. It was developed to solve long-lasting calculations on sparse areas. (Note: a similar technology is supported by Cognos TM/1 and Infor PM OLAP under the names Feeders or Accelerators.)
Jedox In-Memory DB uses an extension of the rules syntax to identify data sources that the user thinks are important for rule calculation. An example of a marked rule is:
['Net Income'] = B: [['Revenue']] - ['Expenses']
In rules pseudo-code it would look like this:
['Net Income'] = B: IF(['Revenue'] != 0, ['Revenue'] - ['Expenses'], 0)
The green part of the rule is evaluated only for those cells that are filtered by the blue part (if condition). The blue filter part runs once after the rule is defined or after server startup, and the coordinates of those cells that fit the condition are cached. This caching can take some time and use a lot of memory if many cells are involved.
The logical error in the example is intentional to illustrate the potential weakness of the concept. ‘Expenses’ typically exist independently of ‘Revenue’ and generate negative Net Income. So with this marked rule, Jedox In-Memory DB will probably generate results different from the same rule without markers.
Therefore we should write:
['Net Income'] = [['Revenue']] - [['Expenses']]
assuming that 'Expenses' data are not as sparse as 'Revenue', or that it can be rule-calculated, "splashing" branch Monthly Expenses for All Products to detail level for days, individual products, sales channels, etc. Thus the 'Net Income' data are as dense as 'Expenses'. In extreme cases, the Marker-Driven Engine can be as slow as the Structure-Driven Engine, except for extra memory demands and slow startup.
Dynamic Marker-Driven Engine
To circumvent some constraints of the Static Marker-Driven Engine, Jedox introduced the Dynamic Marker-Driven Engine (DMDE). By default, Jedox In-Memory DB will use this new Dynamic Marker-Driven Engine for all rules where markers are defined, and for which the Data-Driven Engine (see below) cannot be used. The legacy Static Marker-Driven Engine is no longer used for calculations.
This engine has several advantages:
- Building the so-called "Marker Index" (which indicates which cube slices in a rule calculation can be skipped, thus speeding up Marker-Driven calculation) does not have to be done at Jedox In-Memory DB startup or rule creation/modification, which greatly increases the performance of these actions.
- Since it can be done much faster, the Marker Index can be updated after every cell change. In previous versions of Jedox, the Marker Index was only rebuilt after one million cell changes, which could result in slightly worse performance in some scenarios.
- It eliminates the requirement to define Markers throughout a chain of rules. Instead, Markers can now be defined for individual rules, even if these in turn depend on other, non-marked rules.
Data-Driven Engine
The Data-Driven Engine can process original rules in basic form in an optimal way. It is supported by CPU as well as GPU platforms. It combines the approach used in the Marker-Driven Engine and an optimization focused on grouping cells
The Data-Driven Engine analyzes the plan generated from a database query and creates objects that are specialized to process atomic steps in the plan. We call these objects processors. Each processor provides an output stream of results containing the cell coordinates and its calculated value. The stream can then be used to build a result set sent to the querying application or used as input for another processor.
The most common types of processors are:
- Source processor: selects base values from cube storage
- Arithmetic processors family: addition, subtraction, multiplication
- Transformation processor: transfers data from cell to cell or between cubes
- Aggregation processor: calculates sum aggregations for consolidated cells
Let’s illustrate the processors using the previous example:
[‘Net Income’] = B: [‘Revenue’] - ['Expenses']
This rule generates the following structure of processors: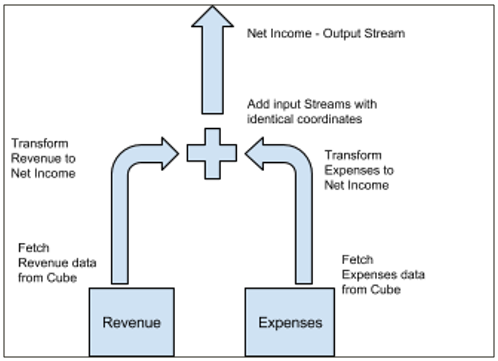
If one of the source processors provides just a few values, the total calculation time is very small in comparison to Structure-Driven Engine. For the correct functionality, the engine requires that all processors provide the output data sorted by cell coordinates the same way. Therefore, it is highly recommended to have those dimensions that are shared among multiple cubes in the same order in every cube.
The following rule-syntax elements are supported by the Data-Driven Engine:
- IF() function
- Comparison operators: >= != == ...
- Mathematical operators: addition, subtraction, multiplication, division
- Simple cell references using PALO.DATA, PALO.MARKER
- DDE will now be used if the rule conforms to its standard, even if a marker is defined
- Dimensions can be mapped via element name from the target cube to the source cube. For example, you could map from a MonthSales dimension in the target cube of the rule to a MonthsOrders dimension in the source cube, as long as the dimensions share at least a subset of matching element names.
- The parameters of PALO.DATA() / PALO.MARKER() have to conform to the other constraints. Additionally, the “current member” syntax is allowed: !'dimension'
- Simple cell references using [] or [[]]
- STET() or CONTINUE()
- Simple functions: SUM, MIN, MAX, AVERAGE
- If simple cell value lookups are used, they have to be uniform. Sum(['2012'],['2013'],['2014']) is supported; Sum(['2012','Jan'],['2013','Feb'],['2014','Mar']) is not supported.
- Logical functions (AND, OR, NOT)
Related links: Data-Driven Engine, Business Rules Overview, Markers
Updated July 3, 2025