Jedox Business Rules enable you to execute complex calculations (division/multiplication, logical and various functions) for Jedox databases. These calculations can be executed for data cubes and for the following system cubes:
- #_GROUP_CUBE_DATA
- #_USER_GROUP
- #_ROLE_RIGHT_OBJECT
- #_USER_USER_PROPERTIES
- #_GROUP_GROUP_PROPERTIES.
The general syntax of rules is [Target] = f[Source], i.e., [Target] is a function of [Source].
[Target] is the area in the cube that is to be calculated using rules. This target area is defined by dimension elements. Elements are not to be listed, if a rule is to apply to all dimension elements. Rules are mapped out per cube.
If a target area is defined in a rule, subsequent rules that describe the same or an overlapping target area are no longer effective. This means that specific rules have to be stored before general rules. The only exception is the rule function CONTINUE, which can switch from one rule into another rule defined on overlapping target areas.
Rules can be constructed in the Rule Editor in the Jedox Modeler; see also Supported Functions for Rules
Terminology
| Area | An area is a set (or sub-cube) of cells created as a combination (or cross-product) of the elements from all dimension subsets defining the area. |
| (GP)GPU | General-purpose computing on Graphics Processing Units. Used in Jedox OLAP Accelerator to speed up rules and consolidation calculations, and for accelerated write-back, including splashing and copy/like operations. |
| Markers | Part of Jedox OLAP Rules syntax, restricting rule calculation to a reduced set of calculated cells to speed up the process. Marker computation has two phases: the first one is pre-processing made directly after rule modification or value writeback. The second calculation, time phase, benefits from the results prepared in first phase. |
| Sparsity | Ratio of the number of cells with non-null results to the total number of cells in the cube (or area). In real-life databases, this ratio is typically very small, e.g. one value per million cells or even less. |
| Subset | Collection of elements from a single dimension. Contains at least one element. Can be up to the full dimension. |
Operators of the Rule Editor
The following operators can be used in rules: + - * / == != < <= > >= | @
These operator differ from Excel operators in the following ways:
- == means equal to (in Excel = is used); only used in the IF function
- != means not equal to (in Excel <> is used); only used in the IF function
- @ is used only for marker
- | is used for concatenation. For example, instead of using CONCATENATE(“Value 1”, “Value2”), you can use “Value 1” | “Value 2”.
Jedox can store 0 in cubes, as well as treat 0 and null differently in comparison with Excel. For more information, see Storing Zero Values. This feature has impact on arithmetic operations or on the rules using the +, -, * or / operators. For example, for the division by 0, Excel returns #error, while Jedox returns the following:
x/0 or 0/x = 0
x/null or null/x = null
for other numeric value of x:
x/x = 1
Comments and formatting
You can add inline comments to your rules to help other users understand their structure and logic. Inline comments can be added with // and block comments can be added with /* … */ (see green text in screenshot below). All comments and formatting persist after the rule is stored in the In-Memory DB.

Cell Type Restriction
Cell type restrictions can be either C: or B: (N: in older versions). If not specified, the rule is enabled for all cells of the target area. C: enables the rule only for cells with a pure consolidated element in at least one dimension, those with no string element in any dimension or under any of the consolidated elements. B: enables the rule for base cells only, i.e., cells with a base element in every dimension. Consolidated values will be calculated as the aggregation of the rule-calculated base cells.
Note that consolidated string elements are treated like base elements by the Rules Engine.
Examples:
If a rule is to apply to base elements only (consolidated elements will be aggregated as usual), the target area may be defined as follows:
[Target]=B: f[Source]Vice versa, it is also possible to restrict the target area to consolidated elements.
[Target]=C: f[Source]To build on the examples we used earlier, change RULE 1 and RULE 2 as follows:
['2015'] = B:123 ['2015','Desktop L'] = B:['2013'] * 1.1Multiple dimension restrictions in rule target and cell references
The Rule Editor does not allow a dimension to be restricted multiple times in one rule.
For example:
['Year':'2019', 'Year':'2020'] = ['Year':'2018']
or
['Year':'2019', 'Year':{'2020','2021'}] = ['Year':'2018']
are not allowed in the Rules Editor, because of double restriction in the Year dimension. The rule target can be restricted to more than one element, but only once, e.g.:
['Year':{'2019','2020','2021'}] = ['Year':'2018']List of target dimensions
Optional occurrence of current member expression !'DimensionName'. Current member means that the element used in dimension ‘DimensionName’ to fetch an input value for the rule is the same as that of the target cell.
Example 1:
[] = PALO.DATA("","#_CONFIGURATION",PALO.EFIRST("","#_CONFIGURATION_"))This rule assigns the same value for all cells of the target cube, and it is read from the first cell of the system cube #_CONFIGURATION. The rule does not contain !‘Dimension’, and therefore it is constant for the whole cube.
Example 2: (based on the Sales cube from the Demo database)
['2014'] = ['2013']As you can see, this rule also does not contain any construction !’Dimension’. However, because it is written in the short (implicit) form, we have to translate the cell reference to the explicit PALO.DATA(…) format to be able to count them all:
['2014'] = PALO.DATA("", "", !'Products', !'Regions', !'Months', !'Years', !'Datatypes', !'Measures')This rule does the same thing, but here we can count occurrences of !’..’. In this case, 30*24*17*1*9*7=771.120 potential unique results have to be evaluated.
Note: the number of potential values that the rule can have is one indicator of calculation time. In the example above, it will take a few microseconds to several seconds, based on the calculation engine that is used.
Defining multiple elements as rule targets
Multiple elements from one dimension can be defined as the target of a rule. The elements are listed inside of curly brackets on the left side of a rule.
Example:
['Months':{'Jan','Feb','Mar'}] = ...Rules with references to removed elements
Rules with element entries that were removed will only be disabled and are still available on the server for manual correction.
Empty strings in PALO.DATA and PALO.MARKER
When an empty string (indicated by "") is used for the <database> or <cube> argument in these two functions, the rule will apply to the current database or cube. For example, if you create a rule in database "Demo", and put an empty string in the <database> argument, the rule will be applied to the Demo database. By using an empty string in this case, the rule will still be valid even if the database is renamed.
Empty strings can be used for the <database> and <cube> arguments in PALO.DATA and PALO.MARKER functions only. They cannot be used in any other functions.
Cell references
Static cell reference
Pros: short syntax, name-independent
Cons: works only with its cube; source elements must be precisely identified
PALO.DATA function
Pros: can access any cube in any database; element names can be complex expressions
Cons: complex syntax; elements are not name-independent - when element name changes, the rule stops working; doesn't react on flexible cube layout changes
Dynamic cell reference (DCR)
DCR shortens and simplifies the use of PALO.DATA and provides support for flexible cube layout.
DCR requires a cube name to be specified in single quotes before square brackets. It can be empty to reference the "self" cube. This name specification is important to distinguish between old intracube cell references, which have many limitations and special STET representation ( STET() can be written as []). Each item MUST specify the source dimension name for the source cube in single quotes, followed by a colon and either the source element in single quotes or general string expression that evaluates an element name.
Benefits of DCR are:
- The dimension can be found automatically. It does not have to be specified.
- The default read element is used if a dimension is added to the source cube.
- The order of parameters is not important.
Example: 'Sales'['Measure':'Units']
Related links: Rule Editor, Rule Engines in Jedox, Markers, Global subsets in OLAP Rules
OFFSET() rules function
OFFSET returns the name of an element that is offset by a specified number of positions from another element. OFFSET is only available for static cell reference and does not work with Dynamic cell references (DCR).
When using the OFFSET function, the rule builder does not have to specify database, dimension, or element since the function is used in context, as shown in the screenshot.
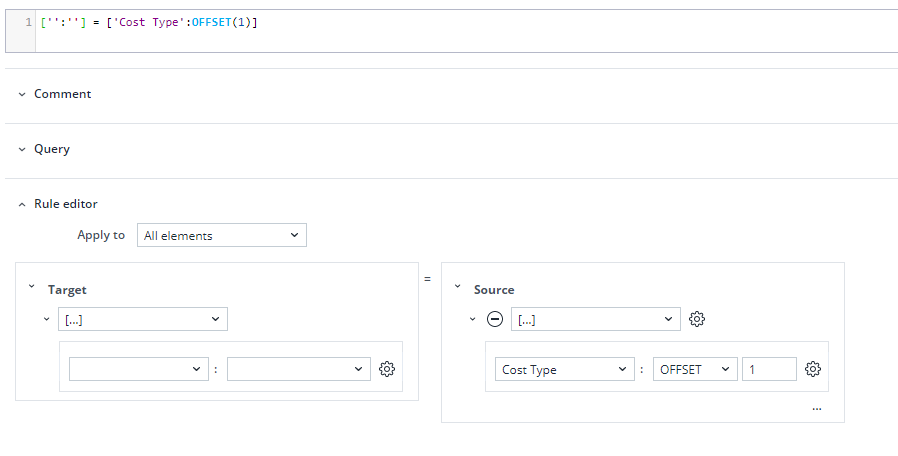
Difference between PALO.EOFFSET() and OFFSET
PALO.EOFFSET() is a general function that requires full context to be specified in parameter list. For example: PALO.OFFSET(<db>,<dim>,<elem>,<offset>)
In comparison, OFFSET has fewer parameters as it is used in the context (database, dimension, and element) of SCR (static cell reference). For example: =[‘dim‘:OFFSET(-1)]
Updated July 3, 2025