Data from a Jedox OLAP cube can be read using a Cube extract. The results of the extract are the paths of the cube cells in the first columns and the related cube cell value in the last column.
Settings
| Connection | Connection name |
| Query cube | Cube name |
| Empty cells | This setting defines the behavior in respect to cells that are not filled or that contain zero values "0" or "". The following options are available:
|
| Base elements only | If set, the numeric cube cells on consolidated cells are excluded from the extract. However, consolidated text cells are extracted in this case. |
| Read rule-based values | If set, rule-based cell values are extracted. If the rule value has the result 0, it is extracted if "empty cells" is set to "excludeEmpty" but not if it's set to "excludeEmptyAndZero". Rule-based cell values of numeric type are extracted, even if the Cell Types setting is set to “only_string”. Rule-based cell values of string type are extracted, even if the Cell Types setting is set to “only_numeric”. |
| Cell types | Specifies whether numeric and/or text cells are extracted. Possible values are: “both” (default), “only_numeric”, and “only_string”.
Tip: if your data requires both numeric and string cell types, you may see improved performance by creating separate extracts for the numeric and string types, rather than one extract with both. |
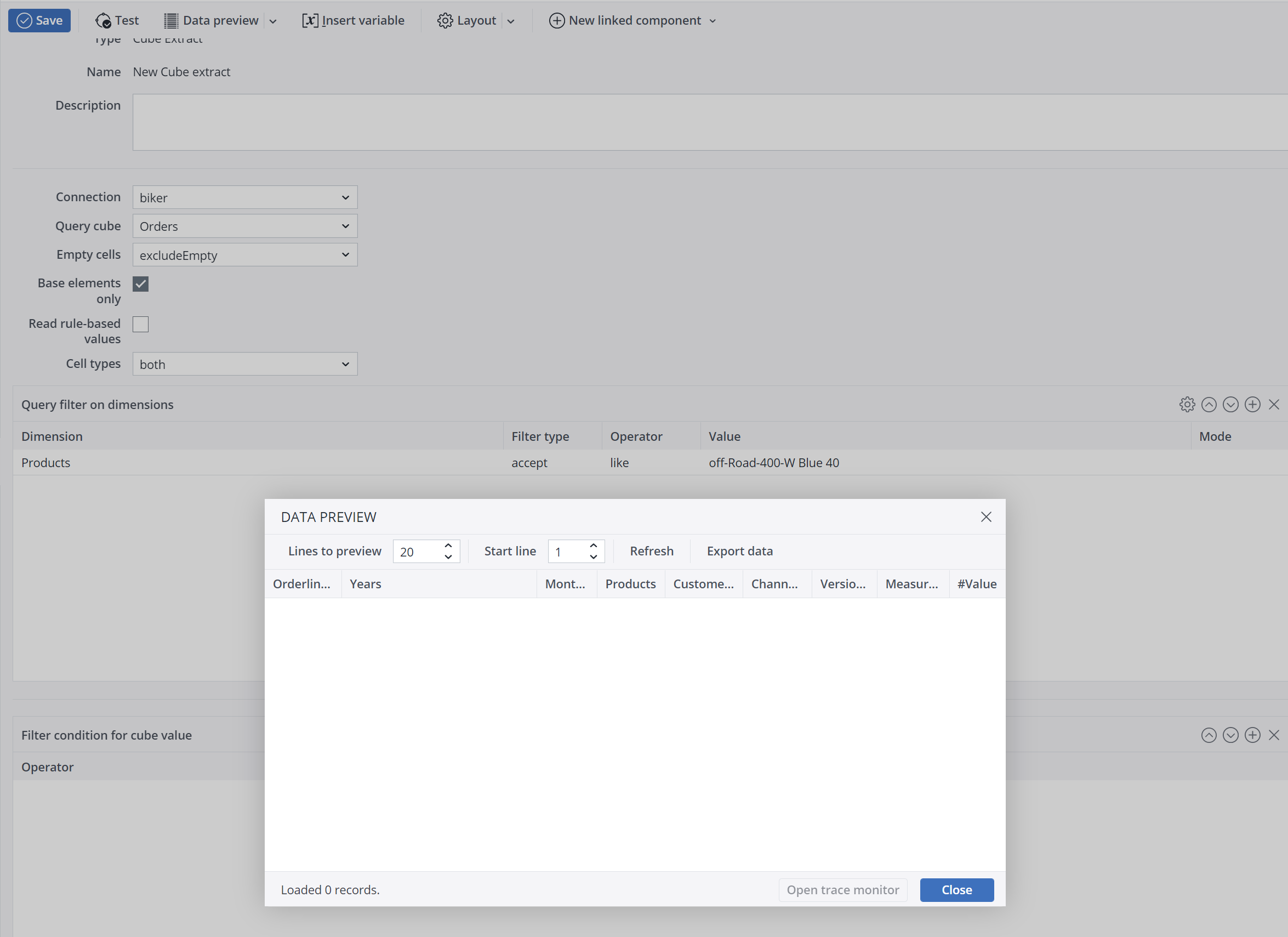
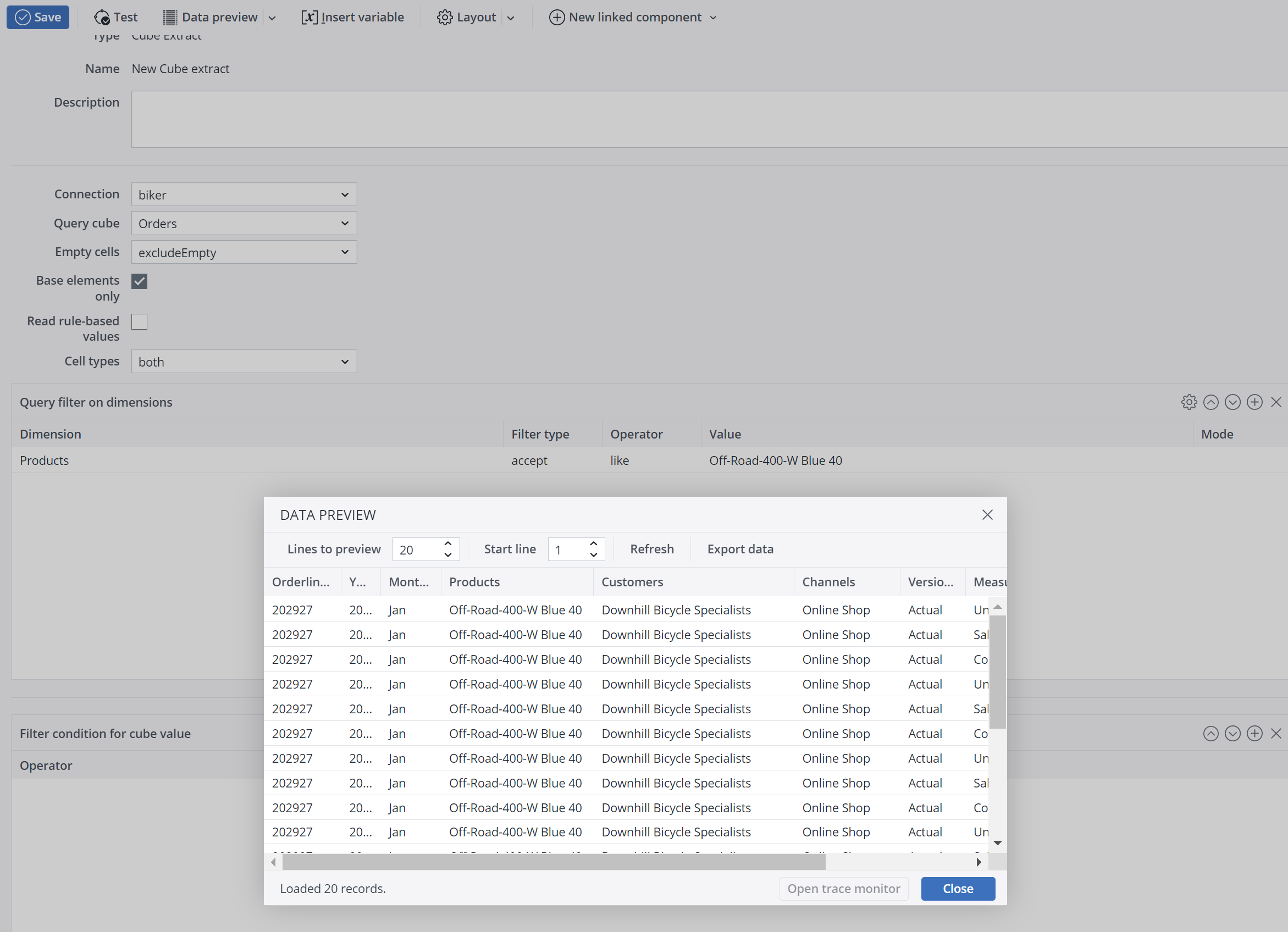
| Query filter on dimensions | A query filter on the dimension allows filtering according to specified elements or values. The filter type can be set to "accept" or "deny" as required. This type of filter allows particular cube areas and/or cube cells to be filtered out. Only cube cells that meet the filter conditions for all dimensions are extracted.
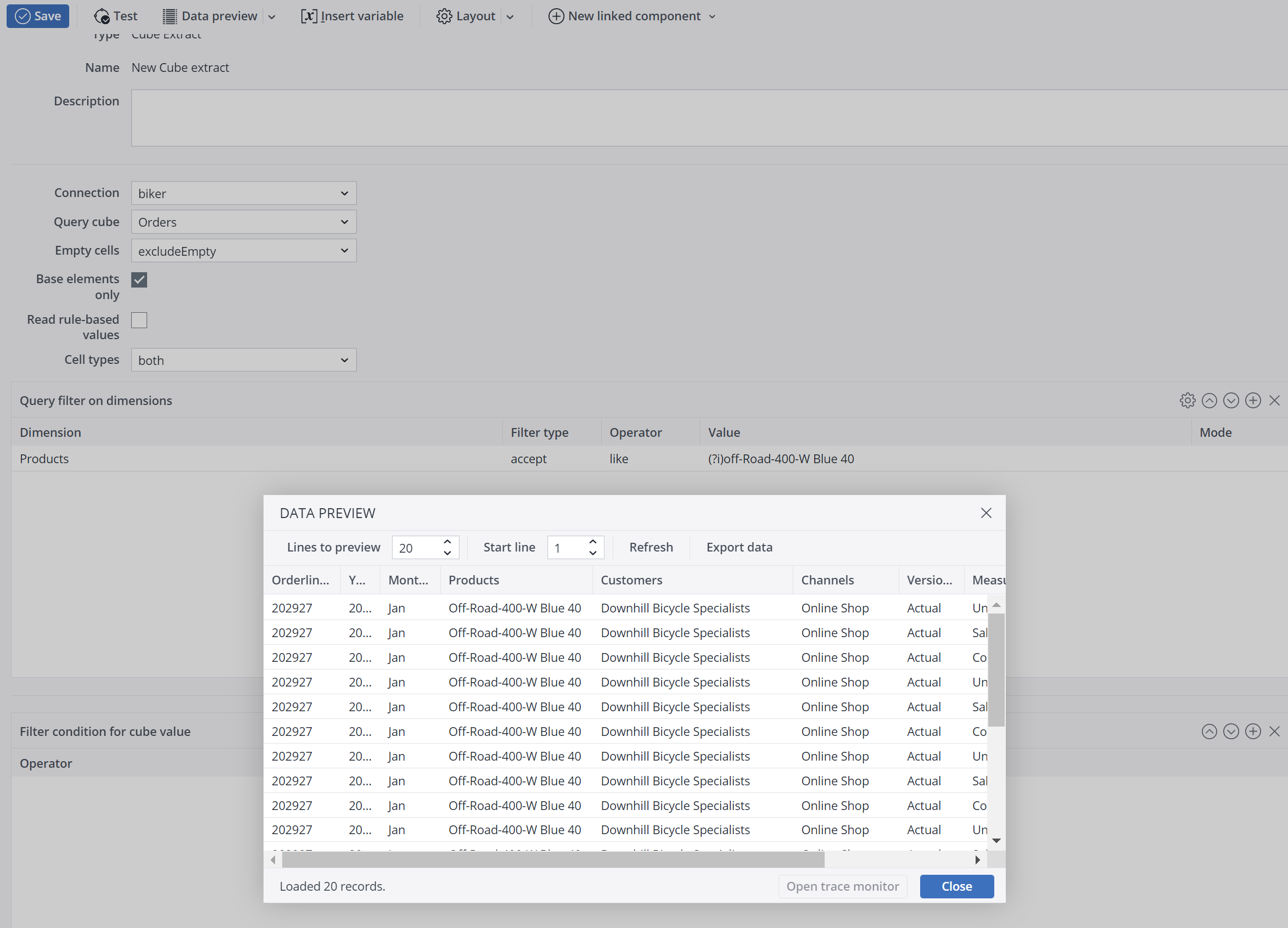
Note: "Equals" is case-insensitive. "Like" (see Query filter for dimensions) is case-sensitive. You can change the case-sensitivity by using a (?) modifier: https://www.regular-expressions.info/modifiers.html
After using the regular expression, the data preview must look like in the example below:
|
| Filter condition for cube value | The result can be filtered on the cube value of the returned cells: - Operator: possible values: - Value (must be numeric value) Example: |
| Logical operator | Multiple conditions are connected with one of these logical operators: "or", "and", "xor". |
| Cube output columns | The cube output columns of the extract can be specified by defining for each column:
In most cases this manual definition is not necessary: by default, all cube dimensions are output columns of the Cube extract with the dimension name as column name and with the order as defined in the cube. The manual definition offers the options of When a cube dimension is omitted from the output columns, the cube values are extracted on the default read element of this dimension. This default read element has to be specified for the dimension in the Modeler. Additionally, no filter condition can be applied on this dimension. |
| Rename value | Name of the last column containing the cube cell value. Default. |
| Retrieve drillthrough data | Only relevant if the cube has been loaded with Drillthrough. If set, the underlying detailed relational drillthrough data of the cube is retrieved. All the defined filters are applied. This option is mainly relevant to verify the correctness of the Drillthrough data of a cube. |
| Block size | The maximal number of cells to export from a cube in a single request (default value: 100.000).
For Lucanet connections: |
| Use caching | Memory, disk or none (default). See article Caching in Extracts. |
The filter options are the same as for the Dimension Extract.
Example
| Extract_Name | Sales_Extract |
| Extract_Type | Cube |
| Connection | Conn_name |
| Query Cube | Sales |
| Ignore Empty Cells | yes |
| Base Elements Only | yes |
| Read Rule-based Values | no |
| Cell Types | both |
Query Filter on Dimensions
| Dimension | Filter Type | Operator | Value | Mode |
| Years | deny | inRange | [2002,2005] | rootToBases |
| Products | accept | equal | Stationary PCs | onlyBases |
Updated July 3, 2025